In today’s data-driven world, capturing not just the latest state of your system but everything that happened is becoming increasingly valuable. That’s where event sourcing comes in—and when combined with Apache Kafka, it becomes a powerful architecture pattern for building resilient, auditable, and real-time systems.
Let’s break it down.
🔁 What Is Event Sourcing?
Traditional applications store only the current state—like the balance of an account. If something goes wrong or you need to understand how you got to this point, you’re out of luck.
Event sourcing flips this idea. It stores a log of all state-changing events, such as:
- “AccountCreated”
- “MoneyDeposited”
- “MoneyWithdrawn”
The current state is then rebuilt by replaying these events in order. This approach enables:
- Full auditability
- Time travel (reconstruct any past state)
- Easier debugging and error recovery
- Rich context for analytics and ML
🛠 Why Kafka for Event Sourcing?
Apache Kafka is the perfect backbone for event sourcing because it is:
- Immutable: Events are append-only and ordered.
- Durable: Events can be retained indefinitely.
- Scalable: Kafka can handle millions of events per second.
- Replayable: Consumers can reprocess historical events as needed.
Kafka naturally aligns with the event sourcing mindset.
📐 Key Architecture Patterns
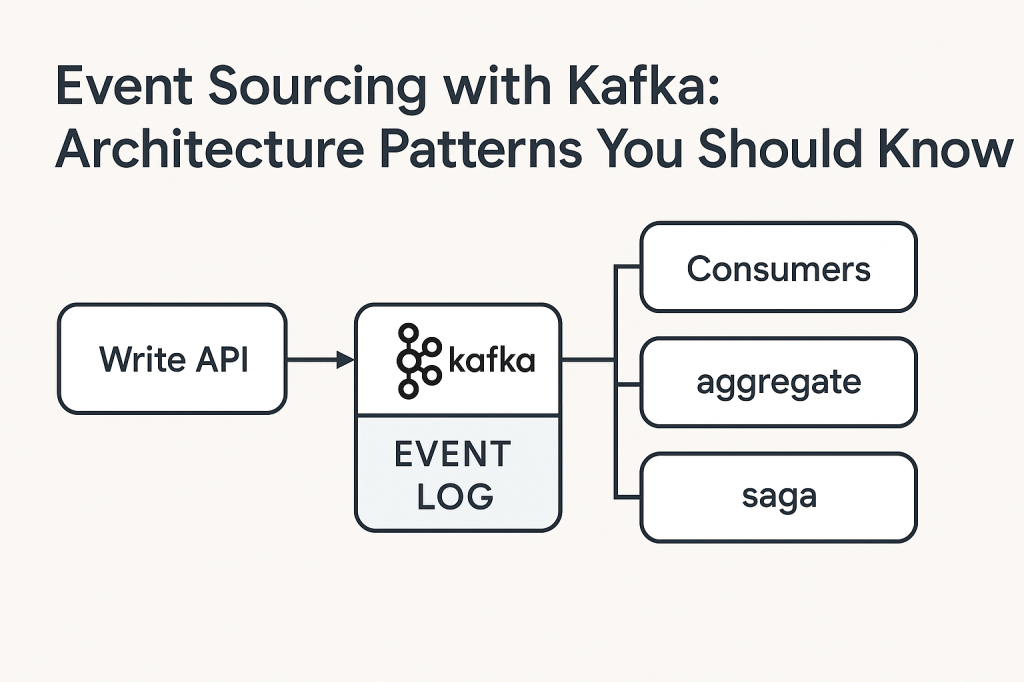
1. Event Store as Source of Truth
Use Kafka topics as your event log. Each topic represents an entity (e.g., user-events, order-events), storing all the changes made to that entity over time.
Pattern:
[Write API] → [Kafka Topic: entity-events] → [Consumers: state builders, analytics, projections]
2. Command and Event Separation (CQRS)
Combine Command Query Responsibility Segregation with event sourcing:
- Commands trigger changes (e.g., “PlaceOrder”).
- Events are emitted to Kafka topics (e.g., “OrderPlaced”).
- Consumers build projections or read models from these events.
Pattern:
Client → Command API → Business Logic → Emit Events → Kafka → Query Layer / Read Models
3. Materialized Views via Stream Processing
Use Kafka Streams or ksqlDB to build real-time views by aggregating or transforming raw events into current state tables.
Examples:
- User balances
- Inventory levels
- Order statuses
Pattern:
Kafka Events → Kafka Streams App → Materialized View → REST API or UI
4. Event Versioning and Schema Evolution
When your event schema changes, use tools like Confluent Schema Registry with Avro/Protobuf to manage versioning and maintain compatibility between producers and consumers.
Tip: Always evolve schemas in a backward-compatible way for seamless replay.
📦 Real-World Use Cases
- Banking: Track every transaction for audit and reconstruction of balances
- E-commerce: Capture all order lifecycle events for customer service and logistics
- IoT: Record every sensor change as a stream of events for anomaly detection
- Healthcare: Log patient interactions and decisions for compliance and ML predictions
🚧 Challenges to Watch For
- Event order and consistency: You may need transaction coordination or partitioning strategies.
- Storage growth: Keeping all events forever increases storage costs.
- Replaying at scale: Replaying millions of events for new projections can be resource-intensive.
Use compacted topics or snapshots to mitigate performance issues.
Event sourcing with Kafka transforms your systems into event-first architectures. Not only do you gain robustness and traceability, but you also unlock a foundation for streaming analytics, ML models, and future-proof business logic.
In a world that never stops changing, keeping a record of how and why things changed might just be your biggest asset.
#Kafka #EventSourcing #Microservices #EventDrivenArchitecture #KafkaStreams #CQRS #SoftwareArchitecture #RealTimeSystems #StreamProcessing

Leave a comment