Photo Credits: https://d2l.ai/chapter_attention-mechanisms-and-transformers/large-pretraining-transformers.html
Transformer models have revolutionized the field of natural language processing (NLP) with their ability to capture contextual information and achieve remarkable results in various tasks. The encoder is a fundamental component of the Transformer architecture, responsible for processing input sequences and generating high-dimensional representations. In this article, we will explore the encoder models of Transformers, discussing their advantages, limitations, and applications.
Understanding the Encoder in Transformers:
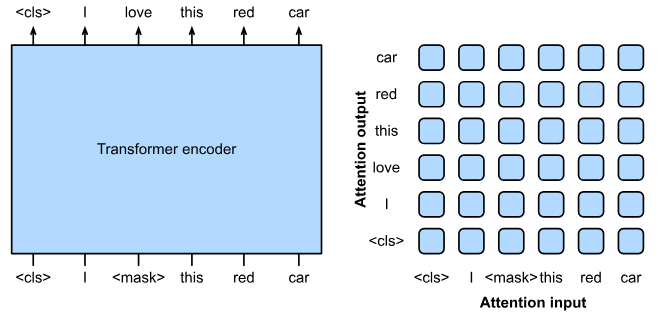
The encoder is a fundamental component of the Transformer architecture that plays a crucial role in understanding and processing input sequences. Its primary task is to encode the input tokens and generate high-dimensional representations that capture the contextual information within the sequence. By leveraging self-attention mechanisms, the encoder efficiently captures both local and global dependencies among the words or subwords in the input.
The encoder consists of multiple layers, with each layer containing a sub-layer that performs self-attention followed by a feed-forward neural network. The self-attention mechanism allows the encoder to weigh the importance of different tokens in the input sequence based on their relevance to each other. This enables the model to focus on key elements and capture the relationships and dependencies between the tokens.
During the self-attention process, each token in the sequence is associated with three types of representations: query, key, and value. These representations are linearly transformed to capture the relationships between different tokens. The attention scores are then computed by measuring the compatibility between the query and the key representations, representing the importance of each token with respect to the others. These attention scores are used to weight the value representations, which are then combined to generate the contextualized representation for each token.
The encoder performs self-attention and the subsequent feed-forward neural network operations in a layer-wise manner. Each layer builds upon the previous one, allowing the model to capture increasingly complex contextual information. By stacking multiple layers, the encoder can capture hierarchical dependencies and capture fine-grained nuances within the input sequence.
The contextualized representations generated by the encoder are rich in semantic information and capture the relationships between the tokens. These representations can be further utilized in downstream tasks such as classification, named entity recognition, or sentiment analysis. Additionally, the encoder’s ability to generate contextual embeddings makes it well-suited for transfer learning, where models can be pretrained on large corpora and fine-tuned for specific tasks with smaller labeled datasets.
Pros of Encoder Models:
- Contextual Representation: The encoder generates contextual embeddings for each input token, representing its meaning in the context of the entire sequence. These embeddings capture rich semantic information, allowing the model to understand the nuances and intricacies of the input.
- Parallel Processing: One significant advantage of encoder models is their ability to process input sequences in parallel. Each token’s representation is computed independently, enabling efficient computation on parallel hardware architectures, resulting in faster training and inference.
- Scalability: Transformers with encoder models are highly scalable. The self-attention mechanism allows the model to capture dependencies across long input sequences without a significant increase in computational complexity. This scalability makes Transformer models well-suited for tasks involving large-scale data.
- Transfer Learning: Encoder models excel in transfer learning scenarios. By pre-training on large corpora, encoder models can learn general language representations that capture a wide range of linguistic patterns. These pre-trained models can then be fine-tuned on specific downstream tasks, leading to improved performance with smaller labeled datasets.
Cons of Encoder Models:
- Lack of Autoregression: Unlike decoder models, encoder models do not have an autoregressive generation mechanism. They focus solely on encoding the input sequence, making them unsuitable for tasks that require sequential generation, such as machine translation or text generation.
- Fixed-length Representations: The encoder generates fixed-length representations for the input sequence. While these representations capture contextual information, they lose fine-grained details, such as word order or position-specific information. This limitation may impact tasks that heavily rely on positional information.
Applications of Encoder Models:
- Sentiment Analysis: Encoder models find extensive application in sentiment analysis tasks. By encoding input text, the model captures the sentiment and emotional context, enabling classification into positive, negative, or neutral sentiment categories.
- Named Entity Recognition: Encoder models are widely used for named entity recognition, where the goal is to identify and classify named entities (such as person names, organizations, or locations) in text. The encoder’s contextual embeddings aid in understanding entity boundaries and their relationships within the text.
- Text Classification: Encoder models excel in text classification tasks, where the goal is to classify documents or sentences into predefined categories. The model encodes the input sequence, capturing the semantic meaning, and produces representations that are fed into a classification layer for prediction.
- Document Similarity: Encoder models are effective in measuring document similarity or computing document embeddings. By encoding entire documents, the model captures the semantic similarity between different texts, facilitating tasks like information retrieval or document clustering.
In conclusion, encoder models in Transformer architectures offer several advantages such as contextual representation, parallel processing, scalability, and transfer learning capabilities. While they have limitations like the lack of autoregression and fixed-length representations, encoder models have demonstrated their effectiveness in various NLP tasks such as sentiment analysis, named entity recognition, text classification, and document similarity. With ongoing research and advancements, encoder models continue to drive progress in natural language processing, enabling a wide range of applications.

Leave a comment